LangChainについては下記で少し扱いましたが、今回はLangGraphと組み合わせて使ってみました。
LangGraphは名のとおり制御フローをグラフ構造を記述するのに向いており、ビジュアルツールなどをつかったワークフローでなくPythonで記述したい場合、有用だと思っています。
https://decode.iiv.jp/blog/202508091968/index.html
https://decode.iiv.jp/blog/202507191951/index.html
特徴的な部分は、_build_graph() です。
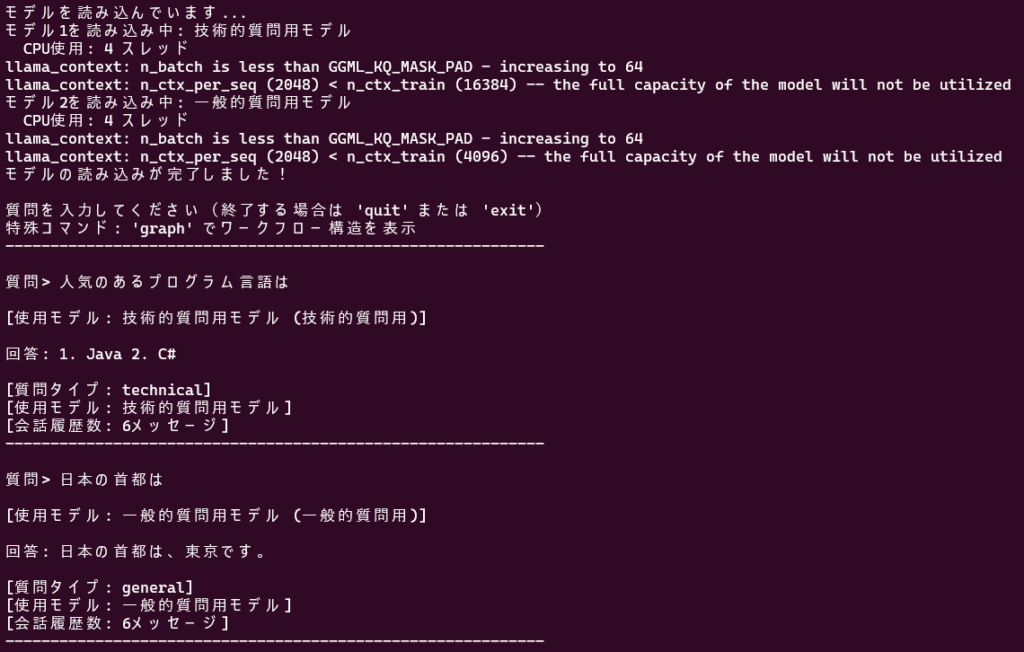
判定結果に応じて選択するノードを切り替えています。このプログラムは質問内容によってLLMを切り替えるデモです。GPUメモリを利用できる設定にしてあります。
#!/usr/bin/env python3
"""
LangGraphのステート管理とワークフローに、LangChainのLCELチェーンを組み合わせた実装
"""
from typing import TypedDict, Annotated, Literal
from langchain_community.llms import LlamaCpp
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langgraph.graph import StateGraph, END
import operator
import json
class GraphState(TypedDict):
"""グラフの状態を管理する型定義"""
messages: Annotated[list[BaseMessage], operator.add]
question: str
question_type: Literal["technical", "general", ""]
model_name: str
response: str
class LLMRouterHybrid:
"""LangChain + LangGraph ハイブリッドルーター"""
def __init__(self, config_path="config.json"):
"""
初期化
Args:
config_path: 設定ファイルのパス
"""
with open(config_path, 'r', encoding='utf-8') as f:
self.config = json.load(f)
print("モデルを読み込んでいます...")
# モデル1: 技術的な質問用(LangChainのLlamaCppラッパー)
print(f"モデル1を読み込み中: {self.config['model1']['name']}")
n_gpu_layers_1 = self.config['model1'].get('n_gpu_layers', 0)
if n_gpu_layers_1 > 0:
print(f" GPU使用: {n_gpu_layers_1} レイヤーをGPUにオフロード")
else:
print(f" CPU使用: {self.config['model1']['n_threads']} スレッド")
self.model1 = LlamaCpp(
model_path=self.config['model1']['path'],
n_ctx=self.config['model1']['n_ctx'],
n_threads=self.config['model1']['n_threads'],
n_gpu_layers=n_gpu_layers_1,
max_tokens=512,
temperature=0.7,
top_p=0.9,
verbose=False,
stop=["質問:", "\n\n"]
)
# モデル2: 一般的な質問用(LangChainのLlamaCppラッパー)
print(f"モデル2を読み込み中: {self.config['model2']['name']}")
n_gpu_layers_2 = self.config['model2'].get('n_gpu_layers', 0)
if n_gpu_layers_2 > 0:
print(f" GPU使用: {n_gpu_layers_2} レイヤーをGPUにオフロード")
else:
print(f" CPU使用: {self.config['model2']['n_threads']} スレッド")
self.model2 = LlamaCpp(
model_path=self.config['model2']['path'],
n_ctx=self.config['model2']['n_ctx'],
n_threads=self.config['model2']['n_threads'],
n_gpu_layers=n_gpu_layers_2,
max_tokens=512,
temperature=0.7,
top_p=0.9,
verbose=False,
stop=["質問:", "\n\n"]
)
print("モデルの読み込みが完了しました!\n")
# 技術的な質問を判定するキーワード
self.technical_keywords = [
'コード', 'プログラム', 'python', 'javascript', 'java', 'c++',
'アルゴリズム', '関数', 'クラス', 'エラー', 'バグ',
'数学', '計算', '方程式', '証明', 'データ構造',
'api', 'データベース', 'sql', 'html', 'css',
'実装', 'デバッグ', 'コンパイル', 'ライブラリ',
'code', 'program', 'algorithm', 'function', 'debug'
]
# LangChainのプロンプトテンプレートを作成
self.prompt_template = PromptTemplate(
input_variables=["question"],
template="質問: {question}\n回答: "
)
# LangChainのLCELチェーンを構築(各モデル用)
self.technical_chain = (
self.prompt_template
| self.model1
| StrOutputParser()
)
self.general_chain = (
self.prompt_template
| self.model2
| StrOutputParser()
)
# LangGraphのワークフローを構築
self.graph = self._build_graph()
@staticmethod
def _clean_text(text: str) -> str:
"""
テキストから不正なUnicode文字を削除
Args:
text: クリーンアップするテキスト
Returns:
クリーンアップされたテキスト
"""
# サロゲートペアや不正な文字を削除
return text.encode('utf-8', errors='ignore').decode('utf-8', errors='ignore')
def classify_question(self, question: str) -> str:
"""
質問を分類する
Args:
question: ユーザーからの質問
Returns:
'technical' または 'general'
"""
question_lower = question.lower()
# 技術的なキーワードが含まれているかチェック
for keyword in self.technical_keywords:
if keyword in question_lower:
return 'technical'
# コードブロックが含まれているかチェック
if '```' in question or 'def ' in question or 'class ' in question:
return 'technical'
return 'general'
def _classify_node(self, state: GraphState) -> GraphState:
"""
質問を分類するノード(LangGraphノード)
Args:
state: 現在の状態
Returns:
更新された状態
"""
question = state["question"]
question_type = self.classify_question(question)
state["question_type"] = question_type
return state
def _route_question(self, state: GraphState) -> Literal["technical_model", "general_model"]:
"""
質問のタイプに基づいてルーティング先を決定(LangGraph条件分岐)
Args:
state: 現在の状態
Returns:
次のノード名
"""
if state["question_type"] == "technical":
return "technical_model"
else:
return "general_model"
def _technical_model_node(self, state: GraphState) -> GraphState:
"""
技術的な質問用モデルで回答を生成するノード
ノード内でLangChainのLCELチェーンを実行
Args:
state: 現在の状態
Returns:
更新された状態
"""
question = self._clean_text(state["question"])
model_name = self.config['model1']['name']
print(f"[使用モデル: {model_name} (技術的質問用)]\n")
# LangChainのLCELチェーンを実行
response = self.technical_chain.invoke({"question": question})
response = self._clean_text(response.strip())
# LangGraphのステートを更新
state["response"] = response
state["model_name"] = model_name
state["messages"].append(AIMessage(content=response))
return state
def _general_model_node(self, state: GraphState) -> GraphState:
"""
一般的な質問用モデルで回答を生成するノード
ノード内でLangChainのLCELチェーンを実行
Args:
state: 現在の状態
Returns:
更新された状態
"""
question = self._clean_text(state["question"])
model_name = self.config['model2']['name']
print(f"[使用モデル: {model_name} (一般的質問用)]\n")
# LangChainのLCELチェーンを実行
response = self.general_chain.invoke({"question": question})
response = self._clean_text(response.strip())
# LangGraphのステートを更新
state["response"] = response
state["model_name"] = model_name
state["messages"].append(AIMessage(content=response))
return state
def _build_graph(self) -> StateGraph:
"""
LangGraphのワークフローを構築
Returns:
コンパイル済みのグラフ
"""
# LangGraphのStateGraphを作成
workflow = StateGraph(GraphState)
# ノードを追加
workflow.add_node("classify", self._classify_node)
workflow.add_node("technical_model", self._technical_model_node)
workflow.add_node("general_model", self._general_model_node)
# エントリーポイントを設定
workflow.set_entry_point("classify")
# 条件分岐エッジを追加(LangGraphのルーティング)
workflow.add_conditional_edges(
"classify",
self._route_question,
{
"technical_model": "technical_model",
"general_model": "general_model"
}
)
# 終了エッジを追加
workflow.add_edge("technical_model", END)
workflow.add_edge("general_model", END)
# グラフをコンパイル
return workflow.compile()
def process_question(self, question: str) -> dict:
"""
質問を処理して回答を生成
LangGraphワークフローを実行
Args:
question: ユーザーからの質問
Returns:
処理結果(状態)
"""
# 質問をクリーンアップ
cleaned_question = self._clean_text(question)
# 初期状態を作成
initial_state: GraphState = {
"messages": [HumanMessage(content=cleaned_question)],
"question": cleaned_question,
"question_type": "",
"model_name": "",
"response": ""
}
# LangGraphのワークフローを実行
result = self.graph.invoke(initial_state)
return result
def visualize_graph(self):
"""
グラフを可視化(要graphviz)
"""
try:
from IPython.display import Image, display
display(Image(self.graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"グラフの可視化にはgraphvizとIPythonが必要です: {e}")
print("\nグラフ構造(テキスト表現):")
print("START → classify → [technical_model | general_model] → END")
print("\n各ノード内でLangChainのLCELチェーンを実行:")
print(" technical_model: PromptTemplate | LlamaCpp(model1) | StrOutputParser")
print(" general_model: PromptTemplate | LlamaCpp(model2) | StrOutputParser")
def main():
try:
router = LLMRouterHybrid()
except FileNotFoundError:
print("エラー: config.jsonが見つかりません。")
print("config.jsonを作成してモデルのパスを設定してください。")
return
except Exception as e:
print(f"エラー: {e}")
import traceback
traceback.print_exc()
return
print("質問を入力してください(終了する場合は 'quit' または 'exit')")
print("特殊コマンド: 'graph' でワークフロー構造を表示")
print("-" * 60)
print()
while True:
try:
question = input("質問> ").strip()
if not question:
continue
if question.lower() in ['quit', 'exit', 'q']:
print("終了します。")
break
# 特殊コマンド: グラフの可視化
if question.lower() == 'graph':
router.visualize_graph()
print()
continue
print()
result = router.process_question(question)
print(f"回答: {result['response']}")
print()
print(f"[質問タイプ: {result['question_type']}]")
print(f"[使用モデル: {result['model_name']}]")
print(f"[会話履歴数: {len(result['messages'])}メッセージ]")
print("-" * 60)
print()
except KeyboardInterrupt:
print("\n\n終了します。")
break
except Exception as e:
print(f"エラーが発生しました: {e}")
import traceback
traceback.print_exc()
print()
if __name__ == "__main__":
main()config.json
{
"model1": {
"name": "技術的質問用モデル",
"path": "codellama-7b.Q4_K_M.gguf",
"n_ctx": 2048,
"n_threads": 4,
"n_gpu_layers": -1,
"description": "コーディング、数学、技術的な質問に特化したモデル"
},
"model2": {
"name": "一般的質問用モデル",
"path": "llama-2-7b-chat.Q4_K_M.gguf",
"n_ctx": 2048,
"n_threads": 4,
"n_gpu_layers": -1,
"description": "雑談、創作、一般的な質問に対応するモデル"
},
"gpu_settings": {
"enabled": false,
"comment": "n_gpu_layers: GPUにオフロードするレイヤー数。0=CPU only, -1=全層GPU, 35=35層をGPUに"
}
}
入力文字によってはUTF-8に関するエラーが発生していたので、チェックロジックがいろいろはいっています。
Claude Code でいろいろ指示をしながら作成しました。